Paper

Code
|
|
|
|
|
Paper |
Code |

|

|

|

|

|

|

|

|

|

|

|

|
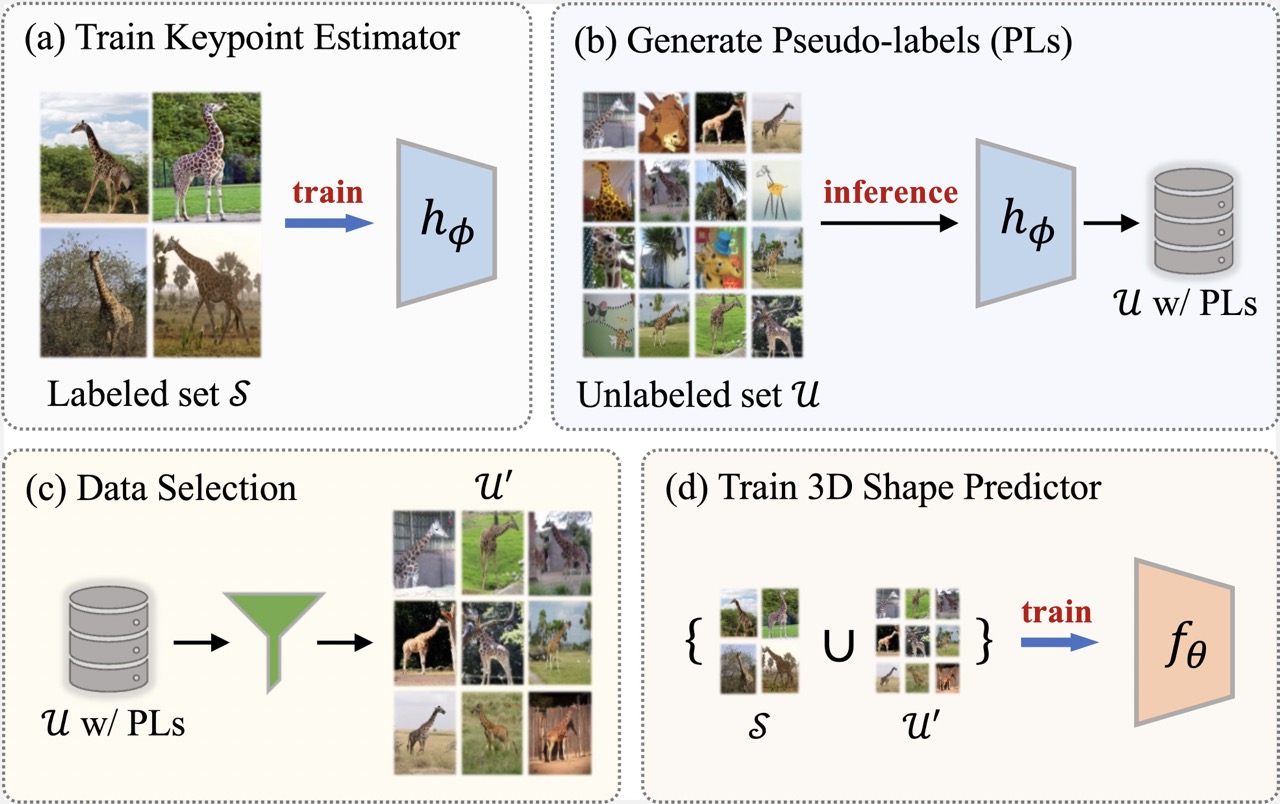
| Overview of the proposed framework. It includes: (a) training a category-specific keypoint estimator with a limited labeled set S (e.g., 50-150 images with keypoint annotations), (b) generating keypoints pseudo-labels on web images, (c) automatic curation of web images using a data selection criterion to create a subset U′, and (d) training a model for 3D shape prediction with images from S and U′. |
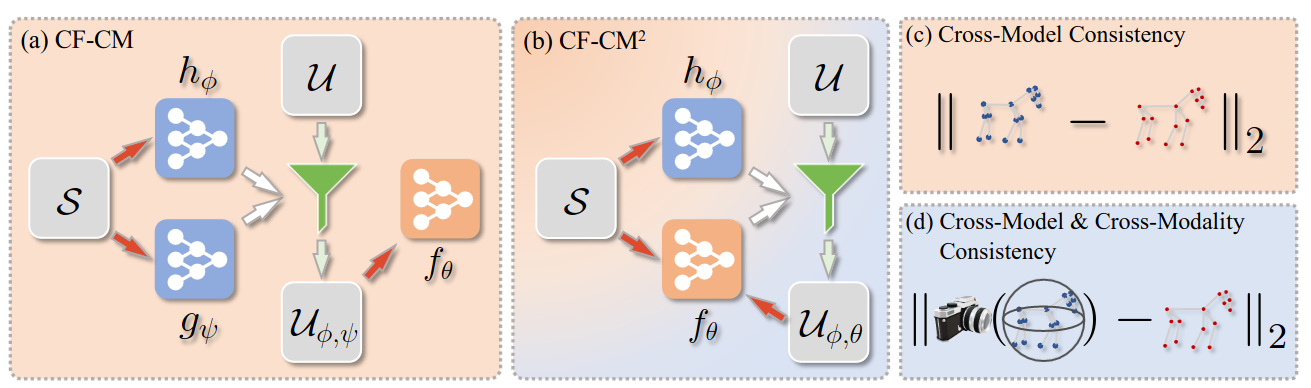
| Given a small set S of images (e.g., 50-150) labeled with 2D keypoints, we train a 2D keypoint estimation network hφ and generate keypoint pseudo-labels on web images (set U). We select a subset of U to train a 3D shape predictor fθ. Two methods for data selection can be seen here: (a) CF-CM: an auxiliary 2D keypoint estimator g generates predictions on U and images with the smallest discrepancy between the keypoint estimates of hφ and gψ are selected (criterion (c)); (b) CF-CM2: fθ is trained with samples from S and generates predictions on U. Images with the smallest discrepancy between the keypoint estimates of hφ and the reprojected keypoints from fθ are selected (criterion (d)) to retrain fθ. |

|

|

|

|

|

|

|

|

|

|

|


|

|

|

|
| Comparison between models trained with and without keypoints PLs. We compare the predictions of CMR trained with and without keypoint pseudo-labels (PLs). For each input image, we show the predicted shape and texture from the inferred camera view, while we rendered the predicted shape and texture from alternative viewpoints. It is clear that using keypoint pseudo-labels substantially improves 3D reconstuction performance. |

|


|

|

|

|

|

|

|

|

|

|

|

|

|

|
| Data selection vs trainig with all downloaded data. We compare the predictions of ACSM trained with 150 images labeled with keypoint and keypoint pseudo-labels from (i) all downloaded web images, (ii) selected images with one of the proposed data selection criteria. For each input image, we show the predicted shape from the inferred camera view and from alternative viewpoints. A data selection method is necessary to effectively utilize web images in our setting. |
Citation |